Informacijos mokslai ISSN 1392-0561 eISSN 1392-1487
2019, vol. 85, pp. 135–147 DOI: https://doi.org/10.15388/Im.2019.85.20
Akies dugno nuotraukų semantinis segmentavimas naudojant konvoliucinius neuroninius tinklus
Ričardas Toliušis
Vilniaus universiteto Duomenų mokslo ir skaitmeninių technologijų institutas
Institute of Data Science and Digital Technologies, Vilnius University
Akademijos g. 4, Vilnius
El. paštas ricardas.toliusis@mif.vu.lt
Olga Kurasova
Vilniaus universiteto Duomenų mokslo ir skaitmeninių technologijų institutas
Institute of Data Science and Digital Technologies, Vilnius University
Akademijos g. 4, Vilnius
El. paštas olga.kurasova@mif.vu.lt
Jolita Bernatavičienė
Vilniaus universiteto Duomenų mokslo ir skaitmeninių technologijų institutas
Institute of Data Science and Digital Technologies, Vilnius University
Akademijos g. 4, Vilnius
El. paštas jolita.bernataviciene@mif.vu.lt
Santrauka. Straipsnyje apžvelgiama akies dugno nuotraukų analizės problematika, semantinio segmentavimo algoritmai, taikomi išskirti akies kraujagysles ir optinį diską. Aptikus jų pokyčius ir anomalijas, galima diagnozuoti įvairias ligas, tokias kaip glaukomą, hipertenziją, diabetinę retinopatiją, makulos degeneraciją ir t. t. Semantiniam segmentavimui atlikti puikiai tinka konvoliuciniai neuroniniai tinklai, ypač U-Net architektūros. Pastaruoju metu buvo sukurta nemažai U-Net modifikacijų, kurios pasiekia puikius efektyvumo rezultatus.
Pagrindiniai žodžiai: U-Net, gilusis mokymasis, dirbtiniai neuroniniai tinklai, semantinis segmentavimas, akies dugnas.
Semantic Segmentation of Eye Fundus Images Using Convolutional Neural Networks
Summary. This article reviews the problems of eye bottom fundus analysis and semantic segmentation algorithms used to distinguish the eye vessels and the optical disk. Various diseases, such as glaucoma, hypertension, diabetic retinopathy, macular degeneration, etc., can be diagnosed through changes and anomalies of the vesssels and optical disk. Convolutional neural networks, especially the U-Net architecture, are well-suited for semantic segmentation. A number of U-Net modifications have been recently developed that deliver excellent performance results.
Keywords: U-Net, deep learning, artificial neural networks, semantic segmentation, eye fundus.
Received: 06/05/2019. Accepted: 12/09/2019.
Copyright © 2018 Ričardas Toliušis, Olga Kurasova, Jolita Bernatavičienė. Published by Vilnius University Press. This is an Open Access article distributed under the terms of the Creative Commons Attribution Licence, which permits unrestricted use, distribution, and reproduction in any medium, provided the original author and source are credited.
1. Įvadas
Automatizuota biomedicininių vaizdų analizė yra aktuali ir perspektyvi dirbtinio intelekto šaka, kuri padeda ypač pagerinti įvairių susirgimų diagnozavimą. Viena medicinos sričių, kurioje tokia analizė gali palengvinti gydytojų darbą, yra akies dugno nuotraukų tyrimas. Iš akies dugno nuotraukų yra nustatomi įvairūs susirgimai, pvz., glaukoma, hipertenzija, diabetinė retinopatija, makulos degeneracija ir kt.
Akies dugno vaizdų analizėje tyrimo objektais gali būti skirtingos akies dalys – kraujagyslės, optinis diskas, regos nervas, makula, lęšiukas. Todėl vaizdų analizėje esminiu momentu tampa semantinis vaizdų segmentavimas, kurio metu kiekvienas vaizdo pikselis yra priskiriamas tam tikrai objekto klasei. Tam yra naudojami įvairūs algoritmai, tačiau pastaruoju metu įsitvirtina dirbtiniai neuroniniai tinklai, o ypač – konvoliuciniai neuroniniai tinklai (angl. Convolutional Neural Networks, CNN). Didelį populiarumą įgijo U-Net architektūra, kuri nuo pat pradžių buvo kuriama biomedicininių vaizdų analizei. U-Net pagrindu buvo sukurta nemažai skirtingų modifikacijų, kurių tikslumas viršija 90 proc.
Standartinę akies dugno nuotraukų analizę galima padalinti į keturias fazes: pirminis vaizdo apdorojimas, objektų išskyrimas, požymių išgavimas ir klasifikavimas (1 pav.). Tačiau sudėtingose architektūrose tų fazių gali būti ir daugiau, jos gali būti atliekamos lygiagrečiai.

1 pav. Akies dugno nuotraukų klasifikavimo procesas
2. Akies vaizdų analizės problematika
Kalbant apie biomedicininius duomenis, viena pagrindinių problemų yra duomenų priėjimo ribotumas. Realiose situacijose neuroninio tinklo mokymui reikia panaudoti tūkstančius anotuotų vaizdų, o laisvai prieinamose akies dugno nuotraukų duomenų bazėse, pvz., DRIVE ar STARE, jų yra vos po kelias dešimtis. Siekiant padidinti vaizdų aibę yra naudojama duomenų augmentacija. Dažniausias taikomas augmentacijos metodas yra geometrinės vaizdų transformacijos. M. Frid-Adar ir kt. (2018) sintetiniam duomenų augmentavimui panaudojo dalinį konvoliucinį neuroninį tinklą GAN (angl. Generative Adversial Network). Naudodamas kompiuterinės tomografijos kepenų vaizdus tinklas generuoja manipuliuodamas įvairiomis augmentavimo technikomis – pasukimai, apvertimai, mastelio keitimas. W. Xianchengas ir kt. (2018) DRIVE duomenų bazės padidinimui nuo 20 vaizdų iki 190 000 panaudojo pilkos skalės konvertavimą, riboto kontrasto adaptyvųjį histogramos išlyginimą (CLAHE) ir gamos korekcijas.
Akies dugno nuotraukų prieinamumą ilgą laiką lėmė ir tai, jog jos dažniausiai daromos medicinos įstaigose labai brangia įranga, tačiau jau yra sukurta ir sąlygiškai nebrangių nešiojamųjų kamerų, pavyzdžiui, tokias kameras gamina „Optomed“, „Zeiss“, „Volk Microclear“ ir kt. O „D-Eye“ sukūrė priedą „iPhone“ išmaniesiems telefonams, kuris jį paverčia akies dugno kamera. B. Shenas ir Sh. Mukai (2017) pristatė mažiau nei 200 dolerių kainuojantį „Rapsbery Pi“ kompiuteriu valdomą kameros prototipą, kuris akį apšviečia infraraudonaisiais spinduliais ir balta šviesa. Naudojant nešiojamuosius fotoaparatus iš dalies galima spręsti vaizdų priėjimo ribotumo problemą, nes atsiranda gerokai daugiau galimybių fotografuoti potencialius ligonius. Tačiau šiuo atveju susiduriama su kita problema – vaizdų kokybe. Nešiojamieji fotoaparatai negali išgauti tokios kokybės nuotraukų, kokia išgaunama naudojant profesionalius stacionarius fotoaparatus. Net su profesionaliais fotoaparatais darytos nuotraukos gali būti netinkamos naudoti. Vaizdų kokybė priklauso nuo fotografavimo procedūros, operatoriaus, apšvietimo, fokusavimo, okliuzijų, plačiai išplitusių pažeidimų, artefaktų. Taip pat sudėtinga nufotografuoti kūdikių ir mažų vaikų akis, jų nuotraukų kokybė būna prastesnė nei suaugusiųjų (Trucco et al., 2013). Tad vienas iššūkių yra apdoroti įėjimo aibės vaizdus ir nustatyti, kurie jų yra tinkami semantiniam segmentavimui.
A. Flemingas ir kt. (2006) vaizdo ryškumą nustatė identifikuodami kraujagysles, o matymo lauką – centruodami makulos regioną, apimdami visą optinį diską ir palikdami mažiausiai du optinio disko skersmenis nuo vaizdo krašto.
Vienas pagrindinių objektų, kurį reikia identifikuoti ir išskirti, yra akies kraujagyslės, kurių pokyčiai stebimi nustatant ligas. Atliekant kraujagyslių tinklo išskyrimą susiduriama su tokiomis problemomis, kuomet arti esančios kraujagyslės gali būti susiliejusios į vieną, dalis plonesnių kraujagyslių pranyksta, tam tikrose vietose yra per silpnai ar per stipriai apšviestos, matomas šviesos spindulys. Be to, sudėtinga atskirti kraujagysles nuo venų, kas yra būtina atliekant kraujagyslių ir venos santykio matavimą.
3. Dirbtinių neuroninių tinklų architektūros
Biomedicininių vaizdų segmentavimui pastaruoju metu ypač sėkmingai panaudojami algoritmai, grįsti dirbtiniais neuroniniais tinklais, o konkrečiau – konvoliuciniais neuroniniais tinklais. Nors pirmasis sėkmingai įgyvendintas 7 lygių konvoliucinis neuroninis tinklas LeNet-5 buvo sukurtas dar 1998-aisiais (LeCun et al., 1998), konvoliuciniai neuroniniai tinklai dėl savo dydžio ir poreikio dideliems kompiuterio resursams ilgą laiką buvo šešėlyje ir retai naudojami tyrimuose. Tačiau pastarąjį dešimtmetį ženkliai padidėjus kompiuterių skaičiavimo galiai atsirado daugiau galimybių panaudoti CNN vaizdų tyrimams.
Didžiausias proveržis įvyko 2012 m., kuomet A. Krizhevsky ir kt. (2012) pristatė AlexNet tinklą, kuris buvo sudarytas iš 5 konvoliucinių sluoksnių ir 3 visiškai sujungtų sluoksnių. ReLU sluoksnis buvo taikomas po kiekvieno konvoliucinio bei visiškai sujungto sluoksnio, o išmetimo (angl. Dropout) sluoksnis po pirmojo ir antrojo visiškai sujungto sluoksnio. AlexNet dideliu skirtumu nugalėjo vaizdų atpažinimo konkurse „ImageNet ILSVRC challenge 2012“. Nuo šio momento CNN smarkiai išpopuliarėjo sprendžiant vaizdų atpažinimo ir klasifikavimo uždavinius, o pastaruosius keletą metų itin aktyviai pradėti naudoti ir semantiniam vaizdų segmentavimui.
„Google“ komanda ILSVR 2014 konkursui pristatė tinklą GoogLeNet, dar vadinamą Inception V1 (Szegedy et al., 2015), kuris konkurse užėmė pirmą vietą. GoogLeNet kurtas remiantis LeNet architektūra, papildomai įtraukiant naują elementą – Inception modulį, naudojamą normalizavimui, vaizdo distorcijoms ir RMSProp funkcijai. Inception modulis yra tarsi atskiras tinklas, turintis tris skirtingo dydžio konvoliucinius sluoksnius (1x1, 3x3, 5x5) ir vieną sujungimo sluoksnį, todėl išėjime paduodami skirtingo tipo požymiai. Į Inception modulį papildomai buvo įtraukta 1x1 dydžio konvoliucijos, todėl ženkliai sumažėjo dimensijos ir skaičiavimo operacijų skaičius. Šiuo metu yra sukurta 4-oji Inception versija.
Viena garsiausių šiuo metu architektūrų laikoma VGGNet, kurią sukūrė K. Simonyan ir A. Zissermanas (2014). ILSVRC 2014 konkurse šis tinklas pasižymėjo labai gera sparta ir užėmė antrą vietą. Buvo sukurtos kelios šio tinklo versijos, geriausius tikslumo rezultatus demonstravo 16 sluoksnių turinti versija. Ši architektūra turi apie 140 milijonų parametrų, kurių dauguma yra pirmajame visiškai sujungtame sluoksnyje. Eksperimentų būdu buvo nustatyta, jog visiškai sujungti sluoksniai gali būti pašalinti iš CNN architektūros, taip neprarandant tinklo efektyvumo, tačiau ženkliai sumažinant reikiamų parametrų kiekį. VGGNet yra viena populiaresnių architektūrų, naudojamų kituose moksliniuose tyrimuose, ją modifikuojant ar kombinuojant su kitais metodais.
Vaizdų atpažinimo srityje pradėjus naudoti giliuosius neuroninius tinklus, jie buvo pritaikyti ir semantiniam segmentavimui. Vienas pirmųjų reikšmingesnių darbų buvo atliktas 2015 metais, kai J. Longas ir kt. (2015) aprašė visiškai konvoliucinių neuroninių tinklų (angl. fully convolutional network, FCN) architektūros panaudojimą semantiniam segmentavimui. Skirtingai nuo klasikinių konvoliucinių neuroninių tinklų, FCN nenaudoja visiškai sujungtų sluoksnių (angl. fully connected layers). Tai leidžia neprisirišti prie absoliučių dimensijų reikšmių, o operuoti santykinėmis, todėl tinklas gali atlikti segmentavimą skirtingo dydžio vaizdams. Taip pat tokios architektūros tinklas pasižymi gerokai didesne sparta nei tipinis konvoliucinis tinklas. Lyginant su AlexNet, FCN segmentavimą atlieka nuo 5 iki 25 kartų greičiau.
V. Badrinarayananas ir kt. (2015) semantiniam vaizdų žymėjimui atlikti sukūrė konvoliucinio tinklo variaciją SegNet, kuri neturi visiškai sujungtų sluoksnių. SegNet remiasi enkoderio–dekoderio principu. Enkoderis – tai 13 konvoliucinių sluoksnių ir vieną sujungimo sluoksnį turintis VGG grįstas tinklas, skirtas sumažinti ir požymių žemėlapiui sukurti, o dekoderis atlieka padidinimo funkciją, sukurdamas išretintą originalaus vaizdo matmenų požymių žemėlapį.
Biomedicininių vaizdų segmentavimui O. Ronnebergeras ir kt. (2015) sukūrė tinklą U-Net. Tinklo struktūra primena U raidę ir esminis jos bruožas, kad sudaryta iš dviejų kelių – mažėjančio kelio kairėje pusėje ir besiplečiančio kelio dešinėje. Mažėjantis kelias mažina vaizdo dydį ir kiekvienoje operacijoje dvigubina požymių kanalų skaičių, o besiplečiantis kelias didina savybių žemėlapį mažindamas požymių kanalų skaičių. U-Net tinklas, apdorodamas biomedicininius vaizdus, 2015 metais laimėjo du ISBI (angl. International Symposium on Biomedical Imaging) vaizdų segmentavimo konkursus.
U-Net tinklo architektūra pavaizduota 2 pav. Ji susideda iš mažėjančio kelio (kairėje pusėje) ir besiplečiančio kelio (dešinėje pusėje). Mažėjantis kelias yra tipinės architektūros konvoliucinis tinklas. Jis susideda iš pasikartojančių 3x3 konvoliucijų (angl. unpadded convolutions), po kurių yra ReLU sluoksnis ir 2x2 dydžio sujungimo (angl. pooling) sluoksnis su žingsniu 2, skirtu sumažinti. Kiekviename sumažinime yra dvigubinamas požymių kanalų skaičius. Kiekvienas žingsnis besiplečiančiame kelyje susideda iš požymių žemėlapio padidinimo naudojant 2x2 konvoliucijas, kurios perpus sumažina požymių kanalų skaičių, susiejant atitinkamai apkirptus požymių žemėlapius iš mažėjančio kelio, ir dvi 3x3 konvoliucijas, po kurių eina ReLU sluoksnis. Šis apkirpimas yra būtinas, kad kiekvienos konvoliucijos metu būtų išvengta pikselių praradimų vaizdo kraštuose.
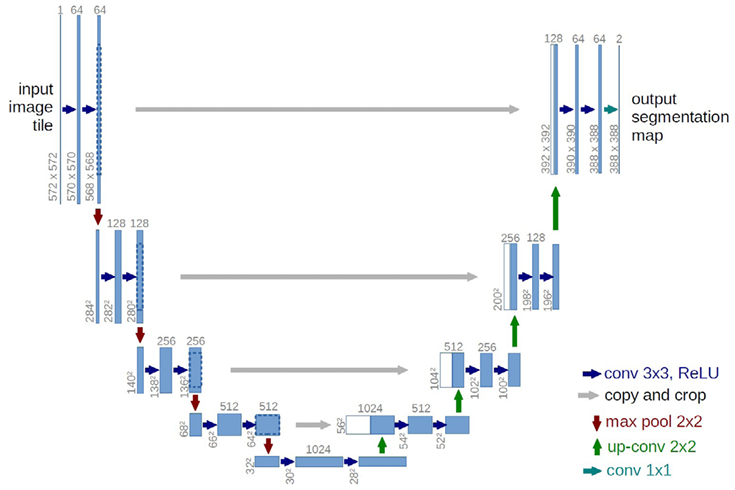
2 pav. U-Net tinklo architektūra (Ronneberger et al., 2015)
Apkirptų požymių žemėlapių sudarymas iš aukštos raiškos vaizdų leidžia tiksliai ir greitai išgauti požymius ir pasiekti gerus rezultatus su mažomis mokymo aibėmis. Tai labai svarbu dirbant su biomedicininiais vaizdais, prie kurių prieiga yra labai ribota.
Paskutinis sluoksnis yra 1x1 konvoliucija, kuri naudojama žemėlapio iš kiekvieno 64 komponentų požymių vektoriaus sudarymui, priskiriant jį siekiamam klasių skaičiui. Iš viso tinklas turi 23 konvoliucinius sluoksnius.
Kadangi U-Net neturi visiškai sujungtų sluoksnių, tai leidžia jam dirbti su skirtingo dydžio vaizdais.
Biomedicininių 3D vaizdų segmentavimui F. Milletari ir kt. (2016) pristatė VNet tinklo architektūrą, kuri struktūriškai primena V raidę ir U-Net tinklo architektūrą. Kairėje pusėje vyksta vaizdų sumažinimas, dešinėje – padidinimas iki originalaus dydžio. Tinklas yra padalintas į po tris konvoliucinius sluoksnius turinčius etapus, kuriuose vyksta darbas su skirtingomis vaizdų raiškomis. Kiekvieno etapo pabaigoje yra naudojama likutinė funkcija, kuri, skirtingai nuo U-Net architektūros, užtikrina konvergenciją. Išėjime yra sugeneruojami du požymių žemėlapiai, kuriuos skaičiuoja greitas konvoliucinis sluoksnis, turintis 1x1x1 dydžio branduolį.
ILSVRC 2015 konkurse pirmą vietą užėmė K. He ir kt. (2016) sukurtas ResNet tinklas (angl. Residual Neural Network). Tinklo architektūros idėja yra liekamieji blokai (angl. residual block), dėl kurių kiekvienas sluoksnis naudoja ne tik ankstesnio sluoksnio išėjimus, bet ir originalius nepaliestus duomenis požymių išgavimui. ResNet naudoja trumpesnio kelio jungtis, kad būtų peršokama per 2–3 sluoksnius. Tinklo architektūra pavaizduota 3 pav.
3 pav. ResNet tinklo architektūra (medium.com)
S. Sabour ir kt. (2017) pristatė kapsulinį neuroninį tinklą CapsNet. Tinklo pagrindinis elementas – kapsulė (Hinton et al., 2011), kuri pati yra neuronų sluoksnių rinkinys. Kapsulė išėjimo duomenis pateikia vektoriuje, kuriame pateikiama informacija apie objekto pozą. Tai leidžia išsaugoti objektų pozos informaciją (orientacija, dydis ir pan.) ir, lyginant su įprastais konvoliuciniais tinklais, CapsNet geba kur kas efektyviau atpažinti objektus, kurių poza yra pakitusi, pavyzdžiui, pasuktas dideliu kampu.
4. Akies vaizdų semantinis segmentavimas
Iš akies dugno nuotraukų galima nustatyti įvairias akies, širdies ir kraujotakos ligas. Analizuojant akies dugno nuotraukas, esminis momentas yra išskirti akies dalį, pagal kurią bus vykdomas susirgimų diagnozavimas. Tam naudojami semantinio segmentavimo algoritmai. Vienas esminių objektų yra akies kraujagyslių tinklas, iš kurio pakitimų yra nustatomos tokios ligos kaip diabetinė retinopatija, glaukoma, makulos degeneracija, choroidinė neovaskuliarizacija, hipertenzija, insultas.
Vieni pirmųjų dirbtinius neuroninius tinklus kraujagyslių klasifikacijai iš rentgeno nuotraukų panaudojo R. Nekovei ir Y. Sunas (1995). Jų sukurtas algoritmas remiasi 3 sluoksnių klaidos skleidimo atgal neuroniniu tinklu. Algoritmas aptinka pilkus vaizdų pikselius, kiekvieną jų apdoroja, sukurdamas aplink langą, kuriame aptinka kitus pilkus pikselius. Tokiu būdu slinkdamas per visą nuotrauką algoritmas išskiria visus pilkus rentgeno nuotraukos pikselius, kurie pateikiami neuroniniam tinklui kaip įėjimo duomenys. Mokymo duomenų aibė sudaryta iš rankiniu būdu pasirinktų lopinėlių, kuriuose kraujagyslių ir fono pikselių yra maždaug po lygiai. Šis metodas atpažįstant kraujagysles iš rentgeno nuotraukų pasiekė 92 proc. tikslumą.
Kraujagyslių atskyrimui nuo fono taikomi įvairūs metodai, kuriuos galima suskirstyti į dvi grupes – taisyklėmis grįsti metodai ir mašininio mokymosi metodai (Stabingis et al., 2018). Prie taisyklėmis grįstų metodų priskiriami dvimatis suderintas filtras (angl. two-dimensional matched filter response (2D MFR)), morfologinis metodas, kraujagyslių sekimo metodas. Prie mašininio mokymosi metodų priskiriami k-NN, SVM, Bayesian decision rule, Fuzzy C-means, K-means (Yavuz, Köse, 2017) ir dirbtiniai neuroniniai tinklai.
Algoritmų efektyvumui įvertinti yra taikomi keli metodai. Vienas populiariausių yra ROC (angl. Receiver operating characteristic) kreivė, parodanti, kaip modelis geba atskirti klases. AUC (angl. Area Under Curve) laipsnis parodo ribą žemiau šios kreivės. Idealus skaičius yra 1, o jei jis žemiau 0,5, vadinasi, modelis yra nepatikimas. Kitas taikomas metodas tikslumui nusakyti yra DICE koeficientas, dar vadinamas F-Score.
D. Maji ir kt. (2015) kraujagyslių atskyrimui nuo fono panaudojo dvylikos konvoliucinių neuroninių tinklų grupę. Kiekvienas konvoliucinis neuroninis tinklas sudarytas iš trijų sluoksnių, kurių kiekvienas buvo apmokytas atskirai naudojant 60 000 atsitiktinai parinktų 31x31 dydžio lopinėlių iš 20-ies spalvotų akies dugno vaizdų iš DRIVE duomenų bazės. AUC laipsnis – 0,947.
Dar geresnius tikslumo rezultatus pasiekė P. Liskowski ir kt. (2016). Jų neuroninis tinklas turėjo tris konvoliucinius sluoksnius, vieną sujungimo ir du visiškai sujungtus sluoksnius. Konvoliuciniai sluoksniai naudojo žingsnį 1, o sujungimo – 2. Šio algoritmo AUC siekė 0,972 su DRIVE baze ir 0,9605 su STARE, o klasifikavimo tikslumas viršijo 0,9495 (DRIVE) ir 0,9416 (STARE).
A. Dasgupta ir S. Singhas (2017) kraujagyslių išskyrimui pasiūlė linijinę 8 sluoksnių konvoliucinio tinklo architektūrą. Pirmieji du sluoksniai konvoliuciniai, trečiasis sujungimo, po to vėl du konvoliuciniai, šeštasis – padidinimo (angl. upsampling), skirtas erdvinėms išėjimo dimensijoms padidinti, ir paskutiniai du – konvoliuciniai. Panaudojus daugiaklasę klasifikaciją tinklas buvo mokomas atspėti ne vieną reikšmę, o reikšmių vektorių. Tinklo tikslumas naudojant DRIVE duomenų bazę buvo 95,33 proc., o AUC siekė – 0,974.
Diabetinės retinopatijos diagnozei J. Brownas ir kt. (2018) panaudojo dvi skirtingas neuroninių tinklų architektūras: kraujagyslių segmentavimui U-Net, o klasifikavimui GoogLeNet. Šis algoritmas buvo išbandytas prieš aštuonis žmones ekspertus, turinčius daugiau nei 10 metų patirties medicinoje. Algoritmas pasiekė geresnius rezultatus net prieš 6 iš 8 ekspertų. Geriausias pasiektas AUC laipsnis buvo 0,98.
T. Laibacheris ir kt. (2018) U-Net pagrindu sukūrė naują architektūrą akies kraujagyslių segmentavimui – M2U-Net. Į enkoderį buvo įtraukti apmokyti MobileNetV2 (Sandler et al., 2018) komponentai, o dekoderyje panaudoti mažėjantys butelio kakliuko blokai (angl. contracting bottleneck blocks). Tai leido sumažinti parametrų skaičių nuo 31 milijono (originalus U-Net) iki 0,55 milijono. Ši architektūra pasižymi itin didele sparta bei gerais tikslumo rezultatais pagal AUC – 0,9714 (DRIVE). Kadangi ši architektūra nereikalauja didelių kompiuterio resursų, ji turi dideles panaudojimo perspektyvas įterptinėse sistemose.
Kita svarbi akies dalis yra optinis diskas. Pagal jo pokyčius yra diagnozuojama glaukoma ar diabetinė retinopatija. H. Alghamdi ir kt. (2016) panaudodami konvoliucinį tinklą sukūrė automatinę optinio disko pakitimų aptikimo sistemą. Matuodama disko įdubos ir disko skersmens santykį ji identifikuoja glaukomą, o identifikuodama tam tikrus pažeidimus, pvz., kraujavimą, nustato kitas anomalijas. Klasifikatoriaus mokymui ir savybių išgavimui jie panaudojo kaskadinius klasifikatorius (AdaBoost, Haar-like). Sistema pasižymi didele greitaveika ir geru tikslumu – su STARE duomenų baze pasiektas 86,7 proc., o su DRIVE – net 100 proc. tikslumas.
A. Mitra ir kt. (2018) sukūrė algoritmą optinio disko segmentavimui. Panaudoję 24 sluoksnių konvoliucinį neuroninį tinklą su MESSIDOR vaizdų baze pasiekė 99,05 proc. atpažinimo tikslumą, o su DRIVE – net 99,41 proc. Jų sukurtas tinklas kontekstinę informaciją išgauna tiesiai iš akies nuotraukos, praleisdamas požymių išgavimo fazę, ir be jokio žmogaus įsikišimo.
Efektyvų automatinio segmentavimo algoritmą DRIU (angl. Deep Retinal Image Understanding) (4 pav.), naudojant giliuosius neuroninius tinklus, pasiūlė K. Maninis ir kt. (2016). DRIU atliko ir kraujagyslių, ir optinio disko segmentavimą. Pagrindinis tinklas buvo grįstas VGG architektūra su pašalintais visiškai sujungtais sluoksniais. Galutiniame vaizdų apdorojimo etape buvo pridėti specializuoti sluoksniai, kurių vienas segmentavo kraujagysles, o kitas optinį diską. Tokia architektūra pademonstravo puikius spartos rezultatus, vieną vaizdą segmentuodama per 65–110 ms (greitis priklausė nuo pasirinktos duomenų bazės ir vaizdo dydžio). Tai pranoko daugelio kitų algoritmų pasiektus rezultatus. Kraujagyslių nustatymo tikslumas siekė 0,822 (DRIVE) ir 0,831 (STARE), o optinio disko – 0,971 (DRIONS-DB) ir 0,959 (RIM-ONE). Palyginkime: žmogaus eksperto pasiekti rezultatai nustatant optinio disko pakitimus siekė 0,967 (DRIONS-DB) ir 0,952 (RIM-ONE).

4 pav. DRIU architektūra leidžia atlikti akies kraujagyslių ir optinio disko segmentavimą (Maninis et al., 2016)
A. Sevastopolsky ir kt. (2018) optinio disko ir jo įdubos segmentavimui panaudojo modifikuotą U-Net architektūrą Stack-U-Net, kurios esmė yra tipiškų U-Net arba Res-U-Net (U-Net su liekamosiomis (angl. residual) jungtimis) jungimas į blokus. Didžiausias tikslumas buvo pasiektas panaudojus 15-a Res-U-Net blokų. Pagal DICE koeficientą (F-Score) optinio disko segmentavimo rezultatai buvo 0,96 (DRIONS-DB), 0,95 (RIM-ONE) ir 0,97 (DRISHTI-GS), o disko įdubos segmentavimo – 0,84 (RIM-ONE) ir 0,89 (DRISHTI-GS).
A. Palas ir kt. (2018) glaukomai aptikti sukūrė daugiamodelinį tinklą G-EyeNet. Jis sudarytas iš enkoderio, dekoderio bei klasifikatoriaus. Dekoderis atlikdamas rekonstrukcijos funkciją padeda klasifikatoriui sumažinti praradimus ir pagerinti klasifikavimą. Glaukoma identifikuojama pagal optinio nervo ir kraujagyslių pakitimus. G-EyeNet akies dugno nuotraukose pirmiausia segmentuoja optinį diską, po to išskiria dominantį regioną (angl. Interest of Region, ROI). Identifikuojant glaukomą AUC pasiekė 0,923.
H. Fu ir kt. (2018) pasiūlė daugiakontekstį gilųjį tinklą (angl. Multi-Context Deep Network, MCDN) uždarojo kampo glaukomai aptikti. MCDN architektūroje požymių žemėlapiui sudaryti lygiagrečiai naudojami du VGG-16 tinklai – vienas globaliam vaizdui (visa nuotrauka), kitas lokaliam (iškirptas lopinėlis). Klasifikavimui taikomas SVM metodas. Geriausias pasiektas AUC rezultatas – 0,9456.
Diagnozuojant tam tikras ligas, pavyzdžiui, diabetinę makulos edemą, yra poreikis išskirti akies tinklainę. A. Ben-Cohenas ir kt. (2017) tinklainės segmentavimui atlikti išbandė U-Net tinklo architektūrą. Optinės koherentinės tomografijos (OCT) nuotraukose neuroninis tinklas atliko tinklainės sluoksnio segmentavimą, po to panaudojant Sobelio filtrą buvo nustatomos sluoksnio ribos. Galutinėje fazėje panaudojant Dijkstros algoritmą ribos buvo patikslinamos. Toks segmentavimo algoritmas segmentuojant tinklainės nervo pluošto sluoksnį pagal F-Score pasiekė rezultatą 0,95.
5. Išvados
Automatizuotas akies dugno nuotraukų tyrimas gali gerokai palengvinti gydytojų darbą diagnozuojant įvairius susirgimus. Semantinis vaizdų segmentavimas, kurio metu kiekvienas pikselis priskiriamas tam tikrai objektų klasei, leidžia iš fono išskirti tokias akies dalis kaip kraujagyslės, optinis diskas ar makula. Konvoliuciniai neuroniniai tinklai yra vienas efektyviausių metodų atlikti semantinį segmentavimą. Įvairių mokslininkų atliktų eksperimentų rezultatai rodo, jog tikslumas dažnai viršija 95 proc.
Biomedicininių vaizdų analizėje populiari U-Net konvoliucinio tinklo architektūra. Viena priežasčių – ši architektūra buvo kuriama darbui su biomedicininiais vaizdais. Be to, šis neuroninis tinklas pasižymi tokiomis savybėmis kaip efektyvus skaičiavimo resursų išnaudojimas bei greitas ir tikslus mokymasis su mažomis vaizdų aibėmis. Tai pasiekiama, nes tinklas, lyginant su dauguma kitų architektūrų, gerokai greičiau aptinka reikiamas tikslias detales. Skirtingų autorių darbai rodo, jog U-Net architektūra yra lengvai tobulinama ir pasiekiamas dar geresnis efektyvumas.
Konvoliuciniai tinklai leidžia išskirtose akies dalyse efektyviai aptikti įvairias anomalijas ir nustatyti susirgimus. Sprendžiant šiuos uždavinius susiduriama su įvairiomis problemomis, pvz., kraujagyslių susiliejimu ar išnykimu, per mažu ar per dideliu apšvietimu, netinkamu regėjimo lauku. Dalis šių problemų yra sunkiai sprendžiamos, tad reikalauja tolesnių intensyvių tyrimų, siekiant efektyvesnių rezultatų.
Kadangi biomedicininių vaizdų prieiga yra viena esminių problematikų, tyrimai atliekami su labai mažomis duomenų imtimis, dažniausiai DRIVE ir STARE vaizdų bazėmis, todėl tyrimuose aprašytus metodus reikia validuoti su didesnėmis vaizdų bazėmis. Be to, į šias vaizdų bazes būna atrinktos kokybiškos nuotraukos, o realybėje taip būna ne visada ir tikslumas gali gerokai skirtis.
1 lentelė. Akies dugno nuotraukų segmentavimo algoritmų, naudojančių neuroninius tinklus, apibendrinimas
|
Autoriai |
Architektūra |
Uždavinys |
Vaizdų duomenų |
Matavimo |
Rezultatas |
|
Maji ir kt. (2015) |
12-os CNN junginys |
Kraujagyslių segmentavimas |
DRIVE |
AUC |
0,947 |
|
Liskowski ir kt. (2016) |
CNN |
Kraujagyslių segmentavimas |
DRIVE |
AUC |
0,972 |
|
STARE |
AUC |
0,9605 |
|||
|
Dasgupta ir Singh (2017) |
CNN |
Kraujagyslių segmentavimas |
DRIVE |
AUC |
0,974 |
|
Brown ir kt. (2018) |
GoogLeNet, U-Net |
Diabetinės retinopatijos diagnozė |
Privati |
AUC |
0,98 |
|
Laibacher ir kt. (2018) |
M2U-Net |
Kraujagyslių segmentavimas |
DRIVE |
AUC |
0,9714 |
|
Alghamdi ir kt. (2016) |
CNN |
Optinio disko segmentavimas |
DRIVE |
Tikslumas |
100 % |
|
STARE |
Tikslumas |
86,71 % |
|||
|
Mitra ir kt. (2018) |
CNN |
Optinio disko segmentavimas |
MESSIDOR |
Tikslumas |
99,05 % |
|
Maninis ir kt. (2016) |
CNN DRIU |
Optinio disko segmentavimas |
DRIONS-DB |
Accuracy |
0,959 |
|
F-Score |
0,97 |
||||
|
RIM-ONE v.3 |
Tikslumas |
0,959 |
|||
|
F-Score |
0,96 |
||||
|
Kraujagyslių segmentavimas |
DRIVE |
Tikslumas |
0,822 |
||
|
STARE |
Tikslumas |
0,831 |
|||
|
Sevastopolsky ir kt. (2018) |
Stack-U-Net |
Optinio disko segmentavimas |
DRIONS-DB |
F-Score |
0,96 |
|
RIM-ONE |
F-Score |
0,95 |
|||
|
DRISHTI-GS |
F-Score |
0,97 |
|||
|
Disko įdubos segmentavimas |
RIM-ONE |
F-Score |
0,84 |
||
|
DRISHTI-GS |
F-Score |
0,89 |
|||
|
Pal ir kt. (2018) |
G-EyeNet |
Glaukomos diagnozavimas |
HRF, RIM ONE v.3, DRISHTI-GS ir DRIONS-DB |
AUC |
0,923 |
|
Fu ir kt. (2018) |
MCDN |
Glaukomos diagnozavimas |
Privati |
AUC |
0,9456 |
|
Ben-Cohen ir kt. (2017) |
U-Net |
Tinklainės segmentavimas |
Privati |
F-Score |
0,95 |
Literatūra
ALGHAMDI, Hanan S.; TANG, Hongying Lilian; WAHEEB, Saad; PETO, Tunde (2016). Automatic Optic Disc Abnormality Detection in Fundus Images: A Deep Learning Approach. https://doi.org/10.17077/omia.1042
BADRINARAYANAN, Vijay; HANDA, Ankur; CIPOLLA, Roberto (2015). Segnet: A Deep Convolutional Encoder-decoder Architecture for Robust Semantic Pixel-wise Labelling. arXiv preprint arXiv:1505.07293.
BEN-COHEN, Avi; MARK, Dean; KOVLER, Ilya; ZUR, Dinah; BARAK, Adiel; IGLICKI, Matias; SOFERMAN, Ron (2017). Retinal Layers Segmentation Using Fully Convolutional Network in OCT Images. RSIP Vision.
BROWN, James M.; CAMPBELL, J. Peter; BEERS, A.; CHANG, Ken; OSTMO, Susan; CHAN, R. V. Paul; DY, Jennifer; ERDOGMUS, Deniz; IOANNIDIS, Stratis; KALPATHY-CRAMER, Jayashree; CHIANG, Michael. F. (2018). Automated Diagnosis of Plus Disease in Retinopathy of Prematurity Using Deep Convolutional Neural Networks. JAMA Ophthalmology, vol. 136, no. 7, p. 803–810. https://doi.org/10.1001/jamaophthalmol.2018.1934
DASGUPTA, Avijit; SINGH, Sonam (2017). A Fully Convolutional Neural Network Based Structured Prediction Approach towards the Retinal Vessel Segmentation. IEEE 14th International Symposium on Biomedical Imaging (ISBI 2017), IEEE, p. 248–251. https://doi.org/10.1109/isbi.2017.7950512
FLEMING, Alan D.; PHILIP, Sam; GOATMAN, Keith A.; OLSON, John A.; SHARP, Peter F. (2006). Automated Assessment of Diabetic Retinal Image Quality Based on Clarity and Field Definition. Investigative Ophthalmology & Visual Science, vol. 47, no. 3, p. 1120–1125. https://doi.org/10.1167/iovs.05-1155
FRID-ADAR, Maayan; DIAMANT, Idit; KLANG, Eyal; AMITAI, Michal; GOLDBERGER, Jacob; GREENSPAN, Hayit (2018). GAN-based Synthetic Medical Image Augmentation for Increased CNN Performance in Liver Lesion Classification. Neurocomputing, vol. 321, p. 321–331. https://doi.org/10.1016/j.neucom.2018.09.013
FU, Huazhu; XU, Yanwu; LIN, Stephen; WONG, Damon Wing Kee; MANI, Baskaran; MAHESH, Meenakshi; AUNG, Tin; LIU, Jiang (2018). Multi-context Deep Network for Angle-closure Glaucoma Screening in Anterior Segment Oct. International Conference on Medical Image Computing and Computer-Assisted Intervention, Springer, p. 356–363. https://doi.org/10.1007/978-3-030-00934-2_40
HE, Kaiming; ZHANG, Xiangyu; REN, Shaoqing; SUN, Jian (2016). Deep Residual Learning for Image Recognition. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, p. 770–778. https://doi.org/10.1109/cvpr.2016.90
HINTON, Geoffrey E.; KRIZHEVSKY, Alex; WANG, Sida D. (2011). Transforming Auto-encoders. International Conference on Artificial Neural Networks, Springer, p. 44–51. https://doi.org/10.1007/978-3-642-21735-7_6
YAVUZ, Zafer; KÖSE, Cemal (2017). Blood Vessel Extraction in Color Retinal Fundus Images with Enhancement Filtering and Unsupervised Classification. Journal of Healthcare Engineering, vol. 2017. https://doi.org/10.1155/2017/4897258
KRIZHEVSKY, Alex; SUTSKEVER, Ilya; HINTON, Geoffrey E. (2012). Imagenet Classification with Deep Convolutional Neural Networks. Advances in Neural Information Processing Systems, p. 1097–1105. https://doi.org/10.1145/3065386
LAIBACHER, Tim; WEYDE, Tillman; JALALI, Sepehr (2018). M2U-Net: Effective and Efficient Retinal Vessel Segmentation for Resource-Constrained Environments. arXiv preprint arXiv:1811.07738.
LECUN, Yann; BOTTOU, Leon; BENGIO, Yoshua; HAFFNER, Patrick (1998). Gradient-based Learning Applied to Document Recognition. Proceedings of the IEEE, vol. 86, no. 11, p. 2278–2324. https://doi.org/10.1109/5.726791
LISKOWSKI, Paweł; KRAWIEC, Krzysztof (2016). Segmenting Retinal Blood Vessels with Deep Neural Networks. IEEE Transactions on Medical Imaging, vol. 35, no. 11, p. 2369–2380, ISSN: 0278-0062. https://doi.org/10.1109/tmi.2016.2546227.
LONG, Jonathan; SHELHAMER, Evan; DARRELL, Trevor (2015). Fully Convolutional Networks for Semantic Segmentation. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, p. 3431–3440. https://doi.org/10.1109/cvpr.2015.7298965
MAJI, Debapriya; SANTARA, Anirban; GHOSH, Sambuddha; SHEET, Debdoot; MITRA, Pabitra (2015). Deep Neural Network and Random Forest Hybrid Architecture for Learning to Detect Retinal Vessels in Fundus Images. 37th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), IEEE, p. 3029–3032. https://doi.org/10.1109/embc.2015.7319030
MANINIS, Kevis-Kokitsi; PONT-TUSET, Jordi; ARBELAEZ, Pablo; VAN GOOL, Luc (2016). Deep Retinal Image Understanding. International Conference on Medical Image Computing and Computer-assisted Intervention, Springer, p. 140–148. https://doi.org/10.1007/978-3-319-46723-8_17
MILLETARI, Fausto; NAVAB, Nassir; AHMADI, Seyed-Ahmad (2016). V-net: Fully Convolutional Neural Networks for Volumetric Medical Image Segmentation. Fourth International Conference on 3D Vision (3DV), IEEE, p. 565–571. https://doi.org/10.1109/3dv.2016.79
MITRA, Anirban; BANERJEE, Priya Shankar; ROY, Sudipta; ROY, Somasis; SETUA, Sanjit Kumar (2018). The Region of Interest Localization for Glaucoma Analysis from Retinal Fundus Image Using Deep Learning. Computer Methods and Programs in Biomedicine, vol. 165, p. 25–35. https://doi.org/10.1016/j.cmpb.2018.08.003
NEKOVEI, Reza; SUN, Ying (1995). Back-propagation Network and Its Configuration for Blood Vessel Detection in Angiograms. Neural Networks, IEEE Transactions on, vol. 6, p. 64–72, Feb. 1995. https://doi.org/10.1109/72.363449.
PAL, Abhishek; MOORTHY, Manav Rajiv; SHAHINA, A. (2018). G-Eyenet: A Convolutional Autoencoding Classifier Framework for the Detection of Glaucoma from Retinal Fundus Images. 25th IEEE International Conference on Image Processing (ICIP), IEEE, p. 2775–2779. https://doi.org/10.1109/icip.2018.8451029
RONNEBERGER, Olaf; FISCHER, Philipp; BROX, Thomas (2015). U-net: Convolutional Networks for Biomedical Image Segmentation. International Conference on Medical Image Computing and Computer-assisted Intervention, Springer, p. 234–241. https://doi.org/10.1007/978-3-319-24574-4_28
SABOUR, Sara; FROSST, Nicholas; HINTON, Geoffrey E. (2017). Dynamic Routing between Capsules. Advances in Neural Information Processing Systems, p. 3856–3866.
SANDLER, Mark; HOWARD, Andrew; ZHU, Menglong; ZHMOGINOV, Andrey; CHEN, Liang-Chieh (2018). Mobilenetv2: Inverted Residuals and Linear Bottlenecks. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, p. 4510–4520. https://doi.org/10.1109/cvpr.2018.00474
SEVASTOPOLSKY, Artem; DRAPAK, Stepan; KISELEV, Konstantin; SNYDER, Blake M.; KEENAN, Jeremy D.; GEORGIEVSKAYA, Anastasia (2018). Stack-U-Net: Refinement Network for Image Segmentation on the Example of Optic Disc and Cup. arXivpreprintarXiv:1804.11294. https://doi.org/10.1117/12.2511572
SHEN, Bailey Y.; MUKAI, Shizuo (2017). A Portable, Inexpensive, Nonmydriatic Fundus Camera Based on the Raspberry Pi® Computer. Journal of Ophthalmology, vol. 2017. https://doi.org/10.1155/2017/4526243
SIMONYAN, Karen; ZISSERMAN, Andrew (2014). Very Deep Convolutional Networks for Large-scale Image Recognition. arXiv preprint arXiv:1409.1556.
STABINGIS, Giedrius; BERNATAVIČIENĖ, Jolita; DZEMYDA, Gintautas; PAUNKSNIS, Alvydas; STABINGIENĖ, Lijana; TREIGYS, Povilas; VAIČAITIENĖ, Ramutė (2018). Adaptive Eye Fundus Vessel Classification for Automatic Artery and Vein Diameter Ratio Evaluation. Informatica, vol. 29, no. 4, p. 757–771. https://doi.org/10.15388/informatica.2018.191
SZEGEDY, Christian; LIU, Wei; JIA, Yangqing; SERMANET, Pierre; REED, Scott; ANGUELOV, Dragomir; ERHAN, Dumitru; VANHOUCKE, Vincent; RABINOVICH, Andrew (2015). Going Deeper with Convolutions. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, p. 1–9. https://doi.org/10.1109/cvpr.2015.7298594
TRUCCO, Emanuele; RUGGERI, Alfredo; KARNOWSKI, Thomas; GIANCARDO, Luca; CHAUM, Edward; HUBSCHMAN, Jean P.; AL-DIRI, Bashir; CHEUNG, Carol Y.; WONG, Damon; ABRÀMOFF, Michael; LIM, Gilbert; KUMAR, Dinesh; BURLINA, Philippe; BRESSLER, Neil M.; JELINEK, Herbert F.; MERIAUDEAU, Fabrice; QUELLEC, Gwénolé; MACGILLIVRAY, Tom; DHILLON, Bal (2013). Validating Retinal Fundus Image Analysis Algorithms: Issues and a Proposal. Investigative Ophthalmology & Visual Science, vol. 54, no. 5, p. 3546–3559. https://doi.org/10.1167/iovs.12-10347
XIANCHENG, Wang; WEI, Li; BINGYI, Miao; HE, Jing; JIANG, Zhangwei; XU, Wen; JI, Zhenyan; HONG, Gu; ZHAOMENG, Shen (2018). Retina Blood Vessel Segmentation Using a U-net Based Convolutional Neural Network. Procedia Computer Science: International Conference on Data Science (ICDS 2018), Beijing, China, 8-9 June 2018.